

图优化学习笔记
参考:
深入理解图优化与g2o:图优化篇
因子图介绍
干货:因子图优化的资源合集
因子图优化 SLAM 研究方向归纳
iSAM2 笔记
图有化(graph-based optimization)是slam中的主流优化算法,一般用于后端优化。g2o是非常流行的图优化库。
优化有三个最重要的因素:目标函数,优化变量,优化约束,优化问题可以简单的描述如下:
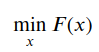
其中𝑥为优化变量,而𝐹(𝑥)为优化函数。此问题称为无约束优化问题,因为我们没有给出任何约束形式。由于slam中优化问题多为无约束优化,所以我们着重介绍无约束的形式。
对于无约束的优化问题,通过梯度求取为零的点,即最小值最大值或者鞍点,然后找其中最小值,解决这个优化:
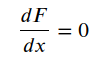
但是更多的时候因为解析形式无法确定,所以采用迭代方式求解。迭代方式关键在于如何选择下降方式和如何选择步长。主要有GN和LM两种方法。
图优化就是把常规优化问题,以图的方式来描述。
图由顶点(Vertex)和边(Edge)组成我们记一个图为G={V,E}。边代表顶点之间的关系,可以有向也可以无向,连接顶点数不限(1到n),一个边连接两个以上顶点的图为超图。SLAM问题就是一个超图问题。
传感器的观测方程和误差方程为:
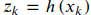
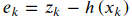
如果我们以𝑥𝑘为优化变量,以min𝑥𝐹𝑘(𝑥𝑘)=‖𝑒𝑘‖为目标函数,就可以求得𝑥𝑘的估计值,进而得到我们想要的东西了。这实际上就是用优化来求解SLAM的思路。
x可以是机器人的位姿(二维或者三维),观测方程可以是两个位姿变换或lidar相机得到的观测数据。
在图中用顶点代表优化变量,以边表示观测方程。,由于边可以连接多个顶点,表示为如下形式:
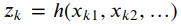

假设一个带有n条边的图,其目标函数如下:
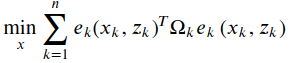
1.e是一个矢量,表示优化变量𝑥𝑘 和𝑧𝑘的符合程度。它越大表示𝑥𝑘 越不符合𝑧𝑘。但是目标函数必须是标量,可以用平方形式表示𝑒(𝑥,𝑧)𝑇𝑒(𝑥,𝑧),为了表示对各个分量值重视程度不同,还需要一个信息矩阵Ω来表示个分量的不一致性。
2.Ω是协方差矩阵的逆,是一个对称矩阵,每个元素Ω𝑖,𝑗作为𝑒𝑖𝑒𝑗 的系数,表示对𝑒𝑖,𝑒𝑗 误差相关性的预计。最简单的是把Ω设置成对角矩阵,对角阵元素的大小表明我们对此误差的重视程度。
3.这里的𝑥𝑘 可以指一个顶点,或者多个点,所以更严谨的方式是写为:
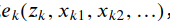
由于这样太繁琐所以简写,由于𝑧𝑘已知,为了数学上的简洁,我们把它写为𝑒𝑘(𝑥𝑘) 的形式。
总体的优化问题变为n条边加和的形式:
如下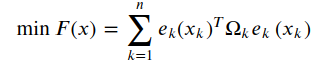
对于视觉SLAM得到的表达是如下:
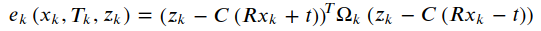
求优化解,需要知道初始点和迭代方向。我们先考虑第k条边𝑒𝑘(𝑥𝑘)。假设初始点为𝑥?𝑘,给它一个增量,边的估计为𝐹𝑘(𝑥?𝑘+Δ𝑥) ,误差从𝑒𝑘(𝑥?) 变为 𝑒𝑘(𝑥?𝑘+Δ𝑥),首先对误差项进行一阶展开:
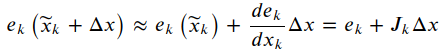
于是对k条边的目标函数项有:
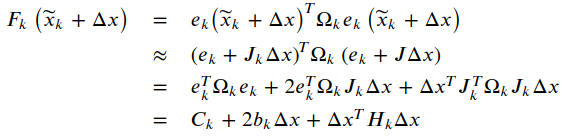
𝐶𝑘 实际就是该边变化前的取值,目标函数𝐹𝑘项改变的值即为:
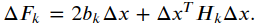
我们的目标是找到Δ𝑥,使得这个增量变为极小值。所以直接令它对于Δ𝑥的导数为零,有:
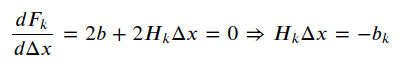
所以得到一个线性方程:
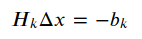
去掉下标如下:
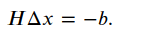
之前限制SLAM发展是因为每一步迭代需要求解一个J和H,而一个图有被认为有很多参数需要优化,后来研究者发现SLAM建图并非全连通图,它往往是很稀疏的。虽然总体目标函数𝐹(𝑥) 有很多项,但某个顶点𝑥𝑘就只会出现在和它有关的边里。

这样会导致很多J为零矩阵,相应的H大部分元素也为零,可以使用稀疏代数库求解。
要补充一点的是,在数值计算中,我们可以给出雅可比和海塞的解析形式进行计算,也可以让计算机去数值计算这两个阵,而我们只需要给出误差的定义方式即可。
𝐹(𝑥) 一个增量Δ𝑥时,直接就写成了𝐹(𝑥+Δ𝑥),这个加法可能没有定义。最简单的就是常见的四维变换矩阵𝑇或者三维旋转矩阵𝑅。它们对加法并不封闭,因为两个变换阵之和并不是变换阵,两个正交阵之和也不是正交阵。
可以使用李代数解决这个问题,即求它们在正切空间里的流形上的梯度。通过指数变换和对数变换,将变换矩阵和旋转矩阵转换为李代数,在李代数上做加法,然后转换到原本的李群中,完成求导。
所以只要我们定义好优化变量的加法,就可以通过图优化求解优化后的结果。
量值重视程度不同,还需要一
引入核函数是因为SLAM可能给出错误边,避免一个错误匹配的路标点对系统优化造成的负面影响。核函数通过将原来的二范数度量替换成一个增长没那么快的函数,保证每条边的误差不会大的没边,这个函数称为鲁棒核函数。
1.选择图里的节点和边,确定它们的参数化形式;
2.往图中加入实际节点和边;
3.选择初值,开始迭代;
4.在每一步迭代计算对应的J和H;
5.求稀疏矩阵𝐻𝑘Δ𝑥=?𝑏𝑘 ,得到梯度方向;
6.继续使用GN和LM进行迭代,迭代结束返回优化值。
实际上,g2o能帮你做好第3-6步,你要做的只是前两步而已。下节我们就来尝试这件事。
使用图的好处是图是稀疏的,可以使用图理论去进行边缘化,消元,加速计算.
位姿图是图优化的一种,不过不考虑对观路标点的优化,优化的只有位姿.
因子图的发展史:
塞巴斯蒂安最开始就是研究图优化的,只不过换了一种模型表达方式,叫做“平方根平滑建图”,这篇文章提出的概念就是批量更新。这里上帝埋下一个伏笔,因为后来他们发现这个模型竟然有一个的彩蛋。因为他们通过平方根的方法构建好了矩阵后,新添加的变量都是从最后一行。
后来呢?Michael觉得,每个矩阵才添加了几行就得更新,能不能简化一点呢?因为每次都是在最后面添加的,所以只要把后面的那几行“搞搞”就行了,就找到了一种Givens 旋转的方法就可以消元了。这时候作者就发了第二篇文章“iSAM”(增量平滑建图)[2],这里面呢,作者用的思路是,正常情况下,用Givens增量消元,如果误差太大,那就固定隔几分钟来个全部优化(又用到了论文[1])。

又过了一段时间,作者发现,为什么要分“增量优化”和“全局优化”两种模式呢? 有没有这样一种方法呢,局部更新如果没有影响全局图,就更新局部;如果影响了全局,就更新全局?或者说有没有一种方法让我影响了多大区域就更新多大面积呢?
后来他就想到树结构(妙啊),找到了一种贝叶斯树的结构。这次呢就不用分“批量”和“增量”两种模式了,而是智能调节,所有的数据都在树结构上,新加进来的放在树根部,受影响的区域肯定是在刚加进来的地方。把受影响的区域提取出来。这就成了最终的贝叶斯树构建的因子图优化了,即iSAM2

作者 Michal 自己还开源了个简单的因子图软件,知道的人不多,其实如果想看源代码,这个更好懂一点,代码量很少,[源码:ori-drs/isam]。他担心大家看不懂,就把这三篇论文写成了一本书《Incremental Smoothing and Mapping》
最后,佐治亚州立大学的这些教授,觉得算法不错呀,干脆封装成一个框架吧,就是GTSAM了。
、最后的最后,才出现了很多以这个框架为基础的应用性论文比如"SLAM ++"[4]和优化型论文“AprilSAM”[5]。
因子图将一个具有多变量的全局函数因子分解,得到几个局部函数的乘积,以此为基础的一个双向图叫做因子图(factor graph)
对于函数g(X1,…,Xn),有以下式子成立:
g(X1,…,Xn)=∏mj=1fj(Sj)
其中,Sj?{X1,…,Xn}。
由以上,我们可以将因子图表示为三元组 G=(X,F,E):
- X={X1,…,Xn} 表示变量结点(variable vertices)
- F={f1,…,fm} 表示因子结点(factor vertices)
- E为边的集合,如果某一个变量结点Xk被因子结点fj的集合Sj包含,那么就可以在Xk和fj之间加入一条无向边
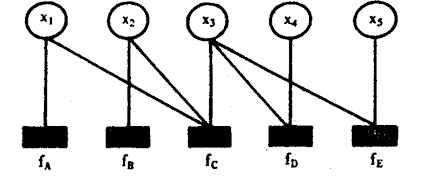
引用自[2]中的例子,现在有一个全局函数g(x1,…,x5),其因式分解方程为:
g(x1,x2,x3,x4,x5)=fA(x1)fB(x2)fC(x1,x2,x3)fD(x3,x4)fE(x3,x5)
其中,各函数表述变量间的关系,可以是条件概率或者其他关系(例如在马尔科夫随机场中的势函数)。
则其对应的因子图如下图所示。
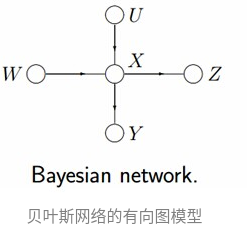
有向图模型,又称作贝叶斯网络(Directed Graphical Models, DGM, Bayesian Network)
但在某些情况下,强制加入结点的边方向是不合适。无向图模型(Undirected Graphical Model, UGM),又称作马尔科夫随机场或者马尔科夫网络(Markov Random Field, MRF or Markov Network)

设X=(X1,…,Xn)和Y=(Y1,…,Ym)都是联合随机变量,若随机变量Y构成一个无向图G=(V,E)表示的马尔科夫随机场,则条件概率分布P(Y∣X)称之为条件随机场(Conditional Random Field, CRF).

贝叶斯网络示例
给出上面图中的贝叶斯网络,根据各个变量间的关系,我们可以得到
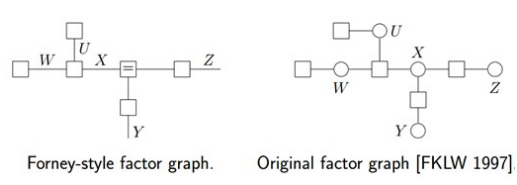
表示为因子图,以下两种形式皆可:
马尔科夫链示例
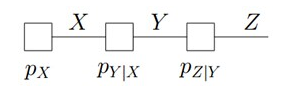
其对应的全局函数可以表示为:
pXYZ(X,Y,Z)=pX(X)pXY(Y∣X)pYZ(Z∣Y)
隐马尔可夫模型示例
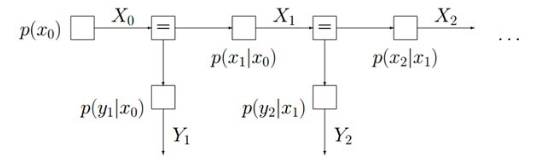
其对应的全局函数可以表示为:
p(X0,…,Xn,Y1,…,Yn)=p(X0)∏nk=1p(Xk∣Xk?1)p(Yk∣Xk?1)
简单来说就是图优化是一次获取所有位姿信息进行优化,因子图优化是逐帧获取逐帧优化,实时且只优化关联帧的位姿信息。
iSAM2 将图优化问题转换成 Bayes tree 的建立、更新和推理问题。原始待优化的问题用 factor graph 表示,factor graph -> Bayes net 建立变量的条件概率,Bayes net -> Bayes tree 建立变量间的更新关系,Bayes tree 从 leaves 到 root 建立的过程,定义了变量逐级更新的 functions,Bayes tree 从 root 到 leaves 可以逐级更新变量值。iSAM2 整套架构建立在概率推理的基础上,和 iSAM 利用 QR 矩阵分解,当有 new factor 时,更新 R 矩阵差别蛮大。
gtsam 时目前因子图增量平滑方面成果的集成,其中囊括了从isam1到isam2 ,贝叶斯树的优化以及之后出现的流行优化。无论是研究还是应用因子图优化,Gtsam都是不二之选。

